请教一下TMS320F28069这款DSP的浮点运算能力怎么样?
我做了一个简单测试: 运算同样的代码(表达式有加减乘除法),其中定点运算方式采用放大、移位方式执行。测试发现定点运算的时间是1.54us,但浮点运算的时间是2.85us,相对定点运算,浮点运算时间更长。(执行此部分代码时有屏蔽中断)
我的CCS版本为V5.2,工程配置为:
-v28 -ml -mt –cla_support=cla0 –float_support=fpu32 –vcu_support=vcu0 -g —
Eric Ma:
BenShan,
你可以把你测试的几句代码附上帖子吗?
下面是FPU和定点的对比,相对于定点,FPU编写更方便,不用进入Q格式转换,同时还可以节省编译代码空间。
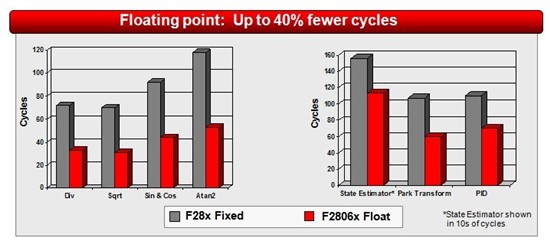
另外fast RTS lib也是结合FPU做的一些数学函数优化库。

Eric
请教一下TMS320F28069这款DSP的浮点运算能力怎么样?
我做了一个简单测试: 运算同样的代码(表达式有加减乘除法),其中定点运算方式采用放大、移位方式执行。测试发现定点运算的时间是1.54us,但浮点运算的时间是2.85us,相对定点运算,浮点运算时间更长。(执行此部分代码时有屏蔽中断)
我的CCS版本为V5.2,工程配置为:
-v28 -ml -mt –cla_support=cla0 –float_support=fpu32 –vcu_support=vcu0 -g —
BenShan liang:
回复 Eric Ma:
Hi, Eric, 我的测试代码如下: 其中stAD_SAMP_CHn、stAD_MIDP_CHn、stAD_REAL_CHn定义为signed int型;stAD_REAL_CH1_F为float型。 //FOR FIXED /*get adc value*/ stAD_SAMP_CH1 = AdcResult.ADCRESULT0 – stAD_MIDP_CH1; stAD_SAMP_CH2 = AdcResult.ADCRESULT1 – stAD_MIDP_CH2; stAD_SAMP_CH3 = AdcResult.ADCRESULT2 – stAD_MIDP_CH3; stAD_SAMP_CH4 = AdcResult.ADCRESULT3 – stAD_MIDP_CH4; stAD_SAMP_CH5 = AdcResult.ADCRESULT4 – stAD_MIDP_CH5; stAD_SAMP_CH6 = AdcResult.ADCRESULT5 – stAD_MIDP_CH6; stAD_SAMP_CH7 = AdcResult.ADCRESULT6 – stAD_MIDP_CH7; stAD_SAMP_CH8 = AdcResult.ADCRESULT7 – stAD_MIDP_CH8; stAD_SAMP_CH9 = AdcResult.ADCRESULT8 – stAD_MIDP_CH9; stAD_SAMP_CH10 = AdcResult.ADCRESULT9 – stAD_MIDP_CH10; stAD_SAMP_CH11 = AdcResult.ADCRESULT10 – stAD_MIDP_CH11; stAD_SAMP_CH12 = AdcResult.ADCRESULT11 – stAD_MIDP_CH12; stAD_SAMP_CH13 = AdcResult.ADCRESULT12 – stAD_MIDP_CH13; stAD_SAMP_CH14 = AdcResult.ADCRESULT13 – stAD_MIDP_CH14; stAD_SAMP_CH15 = AdcResult.ADCRESULT14 – stAD_MIDP_CH15; stAD_SAMP_CH16 = AdcResult.ADCRESULT15 – stAD_MIDP_CH16; /*calculate the real value*/ stAD_REAL_CH1 = (int16_t)(((int32_t)stAD_SAMP_CH1 * cRatio_CH1) >> 12); stAD_REAL_CH2 = (int16_t)(((int32_t)stAD_SAMP_CH2 * cRatio_CH2) >> 12); stAD_REAL_CH3 = (int16_t)(((int32_t)stAD_SAMP_CH3 * cRatio_CH3) >> 12); stAD_REAL_CH4 = (int16_t)(((int32_t)stAD_SAMP_CH4 * cRatio_CH4) >> 12); stAD_REAL_CH5 = (int16_t)(((int32_t)stAD_SAMP_CH5 * cRatio_CH5) >> 12); stAD_REAL_CH6 = (int16_t)(((int32_t)stAD_SAMP_CH6 * cRatio_CH6) >> 12); stAD_REAL_CH7 = (int16_t)(((int32_t)stAD_SAMP_CH7 * cRatio_CH7) >> 12); //FOR FLOAT /*get adc value*/ stAD_SAMP_CH1 = AdcResult.ADCRESULT0 – stAD_MIDP_CH1; stAD_SAMP_CH2 = AdcResult.ADCRESULT1 – stAD_MIDP_CH2; stAD_SAMP_CH3 = AdcResult.ADCRESULT2 – stAD_MIDP_CH3; stAD_SAMP_CH4 = AdcResult.ADCRESULT3 – stAD_MIDP_CH4; stAD_SAMP_CH5 = AdcResult.ADCRESULT4 – stAD_MIDP_CH5; stAD_SAMP_CH6 = AdcResult.ADCRESULT5 – stAD_MIDP_CH6; stAD_SAMP_CH7 = AdcResult.ADCRESULT6 – stAD_MIDP_CH7; stAD_SAMP_CH8 = AdcResult.ADCRESULT7 – stAD_MIDP_CH8; stAD_SAMP_CH9 = AdcResult.ADCRESULT8 – stAD_MIDP_CH9; stAD_SAMP_CH10 = AdcResult.ADCRESULT9 – stAD_MIDP_CH10; stAD_SAMP_CH11 = AdcResult.ADCRESULT10 – stAD_MIDP_CH11; stAD_SAMP_CH12 = AdcResult.ADCRESULT11 – stAD_MIDP_CH12; stAD_SAMP_CH13 = AdcResult.ADCRESULT12 – stAD_MIDP_CH13; stAD_SAMP_CH14 = AdcResult.ADCRESULT13 – stAD_MIDP_CH14; stAD_SAMP_CH15 = AdcResult.ADCRESULT14 – stAD_MIDP_CH15; stAD_SAMP_CH16 = AdcResult.ADCRESULT15 – stAD_MIDP_CH16; /*calculate the real value*/ stAD_REAL_CH1_F = (float)stAD_SAMP_CH1 * 0.2134256; stAD_REAL_CH2_F = (float)stAD_SAMP_CH2 * 0.2134256; stAD_REAL_CH3_F = (float)stAD_SAMP_CH3 * 0.2134256; stAD_REAL_CH4_F = (float)stAD_SAMP_CH4 * 0.2134256; stAD_REAL_CH5_F = (float)stAD_SAMP_CH5 * 0.2134256; stAD_REAL_CH6_F = (float)stAD_SAMP_CH6 * 0.2134256; stAD_REAL_CH7_F = (float)stAD_SAMP_CH7 * 0.2134256;
请教一下TMS320F28069这款DSP的浮点运算能力怎么样?
我做了一个简单测试: 运算同样的代码(表达式有加减乘除法),其中定点运算方式采用放大、移位方式执行。测试发现定点运算的时间是1.54us,但浮点运算的时间是2.85us,相对定点运算,浮点运算时间更长。(执行此部分代码时有屏蔽中断)
我的CCS版本为V5.2,工程配置为:
-v28 -ml -mt –cla_support=cla0 –float_support=fpu32 –vcu_support=vcu0 -g —
Eric Ma:
回复 BenShan liang:
BenShan,
下面是我的测试代码,开发环境CCSv5.3, 使用的配置是从controlSUITE中导入一个28069的timer_blink程序。加载"rts2800_fpu32.lib", "rts2800_fpu32_fast_supplement.lib", "IQmath_fpu32.lib", 程序load在RAM中。
// fpu test Uint32 temp = 0; float result =0; _iq result1 ; _iq temp1; //断点 clock 清零 result = 0.12*0.12; result = 0.12*0.12; result = 0.12*0.12; result = 0.12*0.12; result = 0.12*0.12; temp = 1; // 断点 clock = 12; 所以使用FPU单元,计算5条乘法指令为12个系统时钟; clock 清零 temp1=_IQ(0.12); // gloable IQ = 24 result1 = _IQmpy(temp1,temp1); result1 = _IQmpy(temp1,temp1); result1 = _IQmpy(temp1,temp1); result1 = _IQmpy(temp1,temp1); result1 = _IQmpy(temp1,temp1); temp = 2; // 断点 clock = 28 ; 使用IQmath库进行运算,使用28个时钟; clock清零
result = 0.125*0.12; result = 0.125*0.12; result = 0.125*0.12; result = 0.125*0.12; result = 0.125*0.12; temp = 1; // 断点 clock = 12;clock 清零 temp1=_IQ(0.12); result1 = temp1>>3; result1 = temp1>>3; result1 = temp1>>3; result1 = temp1>>3; result1 = temp1>>3; temp = 2; // 断点 移3位时clock = 17; 若只移1位 clock =9;
通过上面的测试,可以看出有些时候移位确实会比FPU的效率高一点,但是如果移位数增加了,FPU的效率也会超过移位。
另外FPU在编程上也更方便。希望以上对你有些帮助。
Eric
请教一下TMS320F28069这款DSP的浮点运算能力怎么样?
我做了一个简单测试: 运算同样的代码(表达式有加减乘除法),其中定点运算方式采用放大、移位方式执行。测试发现定点运算的时间是1.54us,但浮点运算的时间是2.85us,相对定点运算,浮点运算时间更长。(执行此部分代码时有屏蔽中断)
我的CCS版本为V5.2,工程配置为:
-v28 -ml -mt –cla_support=cla0 –float_support=fpu32 –vcu_support=vcu0 -g —
JING LI11:
回复 Eric Ma:
你好Eric,
我自己写了程序做AC motor control。
其中有三个中断,ADC采样、0.2ms定时器以及PWM 中断。
我全部采用浮点计算,但是在运行过程一段时间后,程序不执行主循环,但中断依旧可以进去。看到你上面的浮点性能测试,我觉得28335完全可以跑简单的转速电流双闭环。不知道为什么我的程序会出现这个问题?
请教一下TMS320F28069这款DSP的浮点运算能力怎么样?
我做了一个简单测试: 运算同样的代码(表达式有加减乘除法),其中定点运算方式采用放大、移位方式执行。测试发现定点运算的时间是1.54us,但浮点运算的时间是2.85us,相对定点运算,浮点运算时间更长。(执行此部分代码时有屏蔽中断)
我的CCS版本为V5.2,工程配置为:
-v28 -ml -mt –cla_support=cla0 –float_support=fpu32 –vcu_support=vcu0 -g —
Eric Ma:
回复 JING LI11:
你可以先测一下你中断的执行时间,用GPIO口来测,然后看一下CPU是否能够及时处理完中断。
另外注意有把相关中断标志位清零。
ERIC
请教一下TMS320F28069这款DSP的浮点运算能力怎么样?
我做了一个简单测试: 运算同样的代码(表达式有加减乘除法),其中定点运算方式采用放大、移位方式执行。测试发现定点运算的时间是1.54us,但浮点运算的时间是2.85us,相对定点运算,浮点运算时间更长。(执行此部分代码时有屏蔽中断)
我的CCS版本为V5.2,工程配置为:
-v28 -ml -mt –cla_support=cla0 –float_support=fpu32 –vcu_support=vcu0 -g —
JING LI11:
回复 Eric Ma:
Hi Eric,
用GPIO 口测试是不是在中断开始时候GPIO输出高电平,到结束时候输出低电平,用示波器查看?
还有我的程序是一开始可以运行主程序的,只是计算一段时间就不运行主程序了,和数据处理以及数据计算方面有关系么?
请教一下TMS320F28069这款DSP的浮点运算能力怎么样?
我做了一个简单测试: 运算同样的代码(表达式有加减乘除法),其中定点运算方式采用放大、移位方式执行。测试发现定点运算的时间是1.54us,但浮点运算的时间是2.85us,相对定点运算,浮点运算时间更长。(执行此部分代码时有屏蔽中断)
我的CCS版本为V5.2,工程配置为:
-v28 -ml -mt –cla_support=cla0 –float_support=fpu32 –vcu_support=vcu0 -g —
Eric Ma:
回复 JING LI11:
GPIO的测试如你所说。用来测试中断的执行时间。
如果过一段时间就不执行主程序,要么芯片一直在执行中断程序,或是跑飞在哪里。
ERIC


